(판다스 시각화) 서울시 유동인구 데이터 분석 및 시각화
folium을 이용한 개선시급지역 시각화
import pandas as pd
from pandas import Series, DataFrame
import numpy as np
import matplotlib
matplotlib.rcParams['font.family'].insert(0, 'Malgun Gothic')
%matplotlib inline
Open API 활용하여 데이터 가져오기
import requests
response=requests.get('http://openapi.seoul.go.kr:8088/sample/xml/VwsmTrdarFlpopQq/1/5/')
#response.text
response=requests.get('http://openapi.seoul.go.kr:8088/sample/json/VwsmTrdarFlpopQq/1/5/') # xml -> json
#response.text
type(response.text)
str
- json (Java Script Object Notation)
- 키(Key)와 값(Value)로 이루어진 데이터 객체
- 파이썬의 사전(Dict) 데이터 타입과 동일
- json online editor: https://jsoneditoronline.org/
# json test를 사전 타입으로 읽어오기
import json
data = json.loads(response.text)
type(data)
dict
#data
data['VwsmTrdarFlpopQq']['row'][0]['TRDAR_SE_CD_NM']
'골목상권'
# json 데이터 구조 파악
# https://jsoneditoronline.org/
데이터 실전 분석: 서울시 유동인구 분석
1. 데이터 적재
유동인구 = pd.read_excel('data/서울시유동인구/0_유동인구_유동인구기본_2015.xlsx', skiprows=[0, 1, 3])
location = pd.read_excel('data/서울시유동인구/4_유동인구_조사지점정보_2015.xlsx', sheet_name=None,
skiprows=[0, 1, 3])
location.keys()
dict_keys(['유동인구_조사지점정보_2015', 'FTPTH_STLE_CN', 'GU_CD', 'DONG_CD', 'SM_GU_CD'])
조사지점 = location['유동인구_조사지점정보_2015']
구코드 = location['GU_CD']
동코드 = location.get('DONG_CD')
집계구코드 = location.get('SM_GU_CD')
유동인구.head()
| ID유동인구조사 | 조사지점코드 | 조사구분 | 조사요일 | 시간대 | 유동인구수 | 년도 | |
|---|---|---|---|---|---|---|---|
| 0 | 1 | 30-001 | 지하철 | 금 | 07시-08시 | 129.0 | 2015 |
| 1 | 2 | 30-001 | 지하철 | 금 | 08시-09시 | 112.5 | 2015 |
| 2 | 3 | 30-001 | 지하철 | 금 | 09시-10시 | 108.0 | 2015 |
| 3 | 4 | 30-001 | 지하철 | 금 | 10시-11시 | 94.5 | 2015 |
| 4 | 5 | 30-001 | 지하철 | 금 | 11시-12시 | 87.0 | 2015 |
조사지점.head()
| 조사지점코드 | 조사지점명 | 구코드 | 동코드 | 주번지 | 부번지 | 도로명 | 보도너비 | 차선수 | 버스차로유무 | ... | 지구중심상세내용 | 도심부도심지역명 | 용도구분 | 거주유형구분 | 입지유형명 | X좌표 | Y좌표 | 집계구코드 | 년도 | 조사구분 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 01-003 | 신흥모피명품전문크리닝. | 11010.0 | 1101055.0 | 127 | 11 | NaN | 3.0 | 8.0 | 유 | ... | NaN | NaN | 2종주거 | NaN | NaN | 196423.97707 | 455511.52968 | 1.101055e+12 | 2015 | 본조사 |
| 1 | 01-004 | GS25 | 11010.0 | 1101055.0 | 94 | 2 | 세검정로 230 | 3.0 | 7.0 | 유 | ... | NaN | NaN | 2종주거 | NaN | NaN | 196315.80243 | 455621.38262 | 1.101055e+12 | 2015 | 본조사 |
| 2 | 01-005 | 세검정정류장 | 11010.0 | 1101055.0 | 92 | 0 | 세검정길 | 4.0 | 5.0 | 유 | ... | NaN | NaN | 1종주거 | NaN | NaN | 196357.17125 | 455680.82580 | 1.101055e+12 | 2015 | 본조사 |
| 3 | 01-008 | 안성타워內 굿모닝파워공인중개사. | 11010.0 | 1101056.0 | 72 | 72 | NaN | 4.0 | 4.0 | 유 | ... | NaN | NaN | 2종주거 | NaN | NaN | 197904.19277 | 456718.34996 | 1.101056e+12 | 2015 | 본조사 |
| 4 | 01-009 | 복실 손뜨기. | 11010.0 | 1101056.0 | 88 | 46 | NaN | 2.0 | 7.0 | 유 | ... | NaN | NaN | 2종주거 | NaN | NaN | 196360.44943 | 456405.89296 | 1.101056e+12 | 2015 | 본조사 |
5 rows × 37 columns
2. 데이터 탐색
2.1 유동인구 데이터 탐색
유동인구.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 102956 entries, 0 to 102955
Data columns (total 7 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 ID유동인구조사 102956 non-null int64
1 조사지점코드 102956 non-null object
2 조사구분 102956 non-null object
3 조사요일 102956 non-null object
4 시간대 102956 non-null object
5 유동인구수 102956 non-null float64
6 년도 102956 non-null int64
dtypes: float64(1), int64(2), object(4)
memory usage: 5.5+ MB
# 조사구분이 본조사인 데이터만 선택
유동인구 = 유동인구[유동인구.조사구분 == '본조사']
# 목요일 정보를 화요일로 변경
유동인구.조사요일 = 유동인구.조사요일.replace('목','화')
columns = ['조사구분', '조사요일', '시간대']
for col in columns:
print(유동인구[col].value_counts())
print()
본조사 85890
Name: 조사구분, dtype: int64
금 17178
수 17178
월 17178
토 17178
화 17178
Name: 조사요일, dtype: int64
07시-08시 6135
08시-09시 6135
09시-10시 6135
10시-11시 6135
11시-12시 6135
12시-13시 6135
13시-14시 6135
14시-15시 6135
15시-16시 6135
16시-17시 6135
17시-18시 6135
18시-19시 6135
19시-20시 6135
20시-21시 6135
Name: 시간대, dtype: int64
# 유동인구 조사지점 개수
len(유동인구.조사지점코드.unique())
1227
# 조사지점별 조사 횟수 확인
유동인구.조사지점코드.value_counts().value_counts()
70 1227
Name: 조사지점코드, dtype: int64
3.2.2 조사지점 데이터 탐색
조사지점.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 1500 entries, 0 to 1499
Data columns (total 37 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 조사지점코드 1500 non-null object
1 조사지점명 1500 non-null object
2 구코드 1408 non-null float64
3 동코드 1408 non-null float64
4 주번지 1418 non-null object
5 부번지 1373 non-null object
6 도로명 1233 non-null object
7 보도너비 1421 non-null float64
8 차선수 1421 non-null float64
9 버스차로유무 1421 non-null object
10 중앙선여부 1421 non-null object
11 장애물유무 1421 non-null object
12 장애물종류 1421 non-null object
13 보행도로구분 1421 non-null object
14 점자블록유무 1421 non-null object
15 경사로유무 1421 non-null object
16 펜스유무 1421 non-null object
17 버스정류장유무 1421 non-null object
18 기타시설유무 0 non-null float64
19 지하철유무 1421 non-null object
20 횡단보도유무 1421 non-null object
21 보도형태 0 non-null float64
22 글로벌존지역명 0 non-null float64
23 주거지역명 0 non-null float64
24 지역중심명 0 non-null float64
25 지역중심상세명 0 non-null float64
26 지구중심명 0 non-null float64
27 지구중심상세내용 0 non-null float64
28 도심부도심지역명 0 non-null float64
29 용도구분 1273 non-null object
30 거주유형구분 0 non-null float64
31 입지유형명 0 non-null float64
32 X좌표 1413 non-null float64
33 Y좌표 1413 non-null float64
34 집계구코드 1413 non-null float64
35 년도 1500 non-null int64
36 조사구분 1500 non-null object
dtypes: float64(18), int64(1), object(18)
memory usage: 433.7+ KB
# 본조사만 선택
조사지점 = 조사지점[조사지점.조사구분 == '본조사']
조사지점.조사구분.value_counts()
본조사 1227
Name: 조사구분, dtype: int64
# 구코드가 누락된 데이터는 제거
# 해당 데이터는 미활용하기로 결정
조사지점 = 조사지점[조사지점.구코드.notnull()]
# 필요한 칼럼만 조사지점에서 선택
조사지점 = 조사지점[['조사지점코드','조사지점명','구코드','동코드','X좌표','Y좌표']]
3.2.3 데이터 합치기 - 분석에 필요한 컬럼들만 선택 (어떤 분석을 할지에 따라 변경 가능함)
최종데이터 = pd.merge(유동인구, 조사지점)
최종데이터.head()
| ID유동인구조사 | 조사지점코드 | 조사구분 | 조사요일 | 시간대 | 유동인구수 | 년도 | 조사지점명 | 구코드 | 동코드 | X좌표 | Y좌표 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 3067 | 01-003 | 본조사 | 금 | 07시-08시 | 21.0 | 2015 | 신흥모피명품전문크리닝. | 11010.0 | 1101055.0 | 196423.97707 | 455511.52968 |
| 1 | 3068 | 01-003 | 본조사 | 금 | 08시-09시 | 36.0 | 2015 | 신흥모피명품전문크리닝. | 11010.0 | 1101055.0 | 196423.97707 | 455511.52968 |
| 2 | 3069 | 01-003 | 본조사 | 금 | 09시-10시 | 27.0 | 2015 | 신흥모피명품전문크리닝. | 11010.0 | 1101055.0 | 196423.97707 | 455511.52968 |
| 3 | 3070 | 01-003 | 본조사 | 금 | 10시-11시 | 51.0 | 2015 | 신흥모피명품전문크리닝. | 11010.0 | 1101055.0 | 196423.97707 | 455511.52968 |
| 4 | 3071 | 01-003 | 본조사 | 금 | 11시-12시 | 36.0 | 2015 | 신흥모피명품전문크리닝. | 11010.0 | 1101055.0 | 196423.97707 | 455511.52968 |
최종데이터 = pd.merge(최종데이터, 구코드[['구코드','구명']])
최종데이터
| ID유동인구조사 | 조사지점코드 | 조사구분 | 조사요일 | 시간대 | 유동인구수 | 년도 | 조사지점명 | 구코드 | 동코드 | X좌표 | Y좌표 | 구명 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 3067 | 01-003 | 본조사 | 금 | 07시-08시 | 21.0 | 2015 | 신흥모피명품전문크리닝. | 11010.0 | 1101055.0 | 196423.97707 | 455511.52968 | 종로구 |
| 1 | 3068 | 01-003 | 본조사 | 금 | 08시-09시 | 36.0 | 2015 | 신흥모피명품전문크리닝. | 11010.0 | 1101055.0 | 196423.97707 | 455511.52968 | 종로구 |
| 2 | 3069 | 01-003 | 본조사 | 금 | 09시-10시 | 27.0 | 2015 | 신흥모피명품전문크리닝. | 11010.0 | 1101055.0 | 196423.97707 | 455511.52968 | 종로구 |
| 3 | 3070 | 01-003 | 본조사 | 금 | 10시-11시 | 51.0 | 2015 | 신흥모피명품전문크리닝. | 11010.0 | 1101055.0 | 196423.97707 | 455511.52968 | 종로구 |
| 4 | 3071 | 01-003 | 본조사 | 금 | 11시-12시 | 36.0 | 2015 | 신흥모피명품전문크리닝. | 11010.0 | 1101055.0 | 196423.97707 | 455511.52968 | 종로구 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 84835 | 88952 | 25-815 | 본조사 | 화 | 16시-17시 | 672.0 | 2015 | 현대자동차 성내지점 | 11250.0 | 1125066.0 | 211778.66913 | 448392.48055 | 강동구 |
| 84836 | 88953 | 25-815 | 본조사 | 화 | 17시-18시 | 732.0 | 2015 | 현대자동차 성내지점 | 11250.0 | 1125066.0 | 211778.66913 | 448392.48055 | 강동구 |
| 84837 | 88954 | 25-815 | 본조사 | 화 | 18시-19시 | 1077.0 | 2015 | 현대자동차 성내지점 | 11250.0 | 1125066.0 | 211778.66913 | 448392.48055 | 강동구 |
| 84838 | 88955 | 25-815 | 본조사 | 화 | 19시-20시 | 753.0 | 2015 | 현대자동차 성내지점 | 11250.0 | 1125066.0 | 211778.66913 | 448392.48055 | 강동구 |
| 84839 | 88956 | 25-815 | 본조사 | 화 | 20시-21시 | 546.0 | 2015 | 현대자동차 성내지점 | 11250.0 | 1125066.0 | 211778.66913 | 448392.48055 | 강동구 |
84840 rows × 13 columns
최종데이터 = pd.merge(최종데이터, 동코드[['동코드','동명']])
최종데이터
| ID유동인구조사 | 조사지점코드 | 조사구분 | 조사요일 | 시간대 | 유동인구수 | 년도 | 조사지점명 | 구코드 | 동코드 | X좌표 | Y좌표 | 구명 | 동명 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 3067 | 01-003 | 본조사 | 금 | 07시-08시 | 21.0 | 2015 | 신흥모피명품전문크리닝. | 11010.0 | 1101055.0 | 196423.97707 | 455511.52968 | 종로구 | 부암동 |
| 1 | 3068 | 01-003 | 본조사 | 금 | 08시-09시 | 36.0 | 2015 | 신흥모피명품전문크리닝. | 11010.0 | 1101055.0 | 196423.97707 | 455511.52968 | 종로구 | 부암동 |
| 2 | 3069 | 01-003 | 본조사 | 금 | 09시-10시 | 27.0 | 2015 | 신흥모피명품전문크리닝. | 11010.0 | 1101055.0 | 196423.97707 | 455511.52968 | 종로구 | 부암동 |
| 3 | 3070 | 01-003 | 본조사 | 금 | 10시-11시 | 51.0 | 2015 | 신흥모피명품전문크리닝. | 11010.0 | 1101055.0 | 196423.97707 | 455511.52968 | 종로구 | 부암동 |
| 4 | 3071 | 01-003 | 본조사 | 금 | 11시-12시 | 36.0 | 2015 | 신흥모피명품전문크리닝. | 11010.0 | 1101055.0 | 196423.97707 | 455511.52968 | 종로구 | 부암동 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 84835 | 88742 | 25-430 | 본조사 | 화 | 16시-17시 | 2463.0 | 2015 | 신동아생활용품DC마트 | 11250.0 | 1125072.0 | 211375.75228 | 450168.33297 | 강동구 | 암사1동 |
| 84836 | 88743 | 25-430 | 본조사 | 화 | 17시-18시 | 2331.0 | 2015 | 신동아생활용품DC마트 | 11250.0 | 1125072.0 | 211375.75228 | 450168.33297 | 강동구 | 암사1동 |
| 84837 | 88744 | 25-430 | 본조사 | 화 | 18시-19시 | 2160.0 | 2015 | 신동아생활용품DC마트 | 11250.0 | 1125072.0 | 211375.75228 | 450168.33297 | 강동구 | 암사1동 |
| 84838 | 88745 | 25-430 | 본조사 | 화 | 19시-20시 | 1929.0 | 2015 | 신동아생활용품DC마트 | 11250.0 | 1125072.0 | 211375.75228 | 450168.33297 | 강동구 | 암사1동 |
| 84839 | 88746 | 25-430 | 본조사 | 화 | 20시-21시 | 1512.0 | 2015 | 신동아생활용품DC마트 | 11250.0 | 1125072.0 | 211375.75228 | 450168.33297 | 강동구 | 암사1동 |
84840 rows × 14 columns
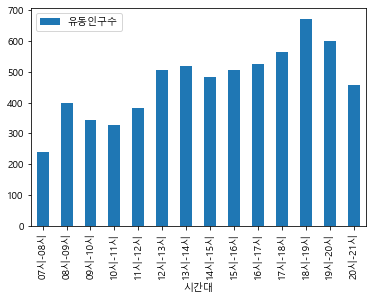
(실습 #1) 유동인구를 시간대 별로 분석하여 시각화하기
ex1 = 최종데이터.pivot_table(index = '시간대', aggfunc = 'mean', values = '유동인구수')
ex1.plot()
<AxesSubplot:xlabel='시간대'>
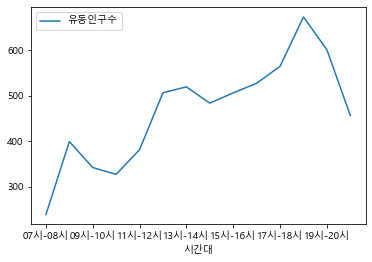
ex1.plot(kind='bar')
<AxesSubplot:xlabel='시간대'>
(실습 #2) 구별 유동인구 통계 분석 및 시각화
구별로 조사지점의 개수가 다르므로, 조사지점 당 평균 유동인구수로 분석
# 구별로 조사지점 개수의 차이가 있는지 확인
최종데이터.pivot_table(index = '구코드', values = '조사지점코드',
aggfunc = Series.nunique)
| 조사지점코드 | |
|---|---|
| 구코드 | |
| 11010.0 | 76 |
| 11020.0 | 70 |
| 11030.0 | 50 |
| 11040.0 | 36 |
| 11050.0 | 39 |
| 11060.0 | 47 |
| 11070.0 | 42 |
| 11080.0 | 43 |
| 11090.0 | 33 |
| 11100.0 | 30 |
| 11110.0 | 71 |
| 11120.0 | 35 |
| 11130.0 | 28 |
| 11140.0 | 54 |
| 11150.0 | 53 |
| 11160.0 | 35 |
| 11170.0 | 47 |
| 11180.0 | 23 |
| 11190.0 | 64 |
| 11200.0 | 33 |
| 11210.0 | 41 |
| 11220.0 | 82 |
| 11230.0 | 80 |
| 11240.0 | 64 |
| 11250.0 | 36 |
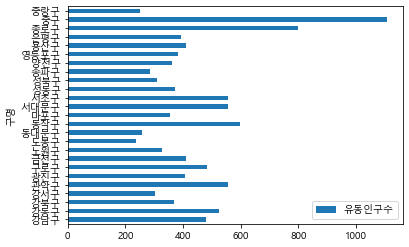
구별인구통계 = 최종데이터.pivot_table(index = '구명', values='유동인구수',
aggfunc = 'mean')
구별인구통계.plot(kind='bar')
<AxesSubplot:xlabel='구명'>
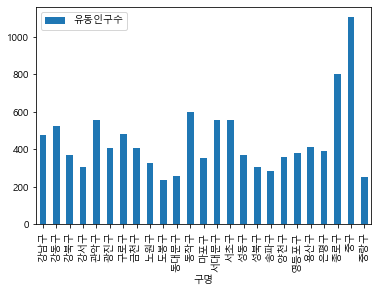
구별인구통계.plot(kind='barh')
<AxesSubplot:ylabel='구명'>
# 지도에 시각화
import folium
map1 = folium.Map(location=[37.566535, 126.9779691999996], zoom_start=10,
zoom_control=False, control_scale=True,
tiles='https://tiles.stadiamaps.com/tiles/outdoors/{z}/{x}/{y}{r}.png',
attr='© <a href="https://stadiamaps.com/">Stadia Maps</a>, © <a href="https://openmaptiles.org/">OpenMapTiles</a> © <a href="http://openstreetmap.org">OpenStreetMap</a> contributors')
map1
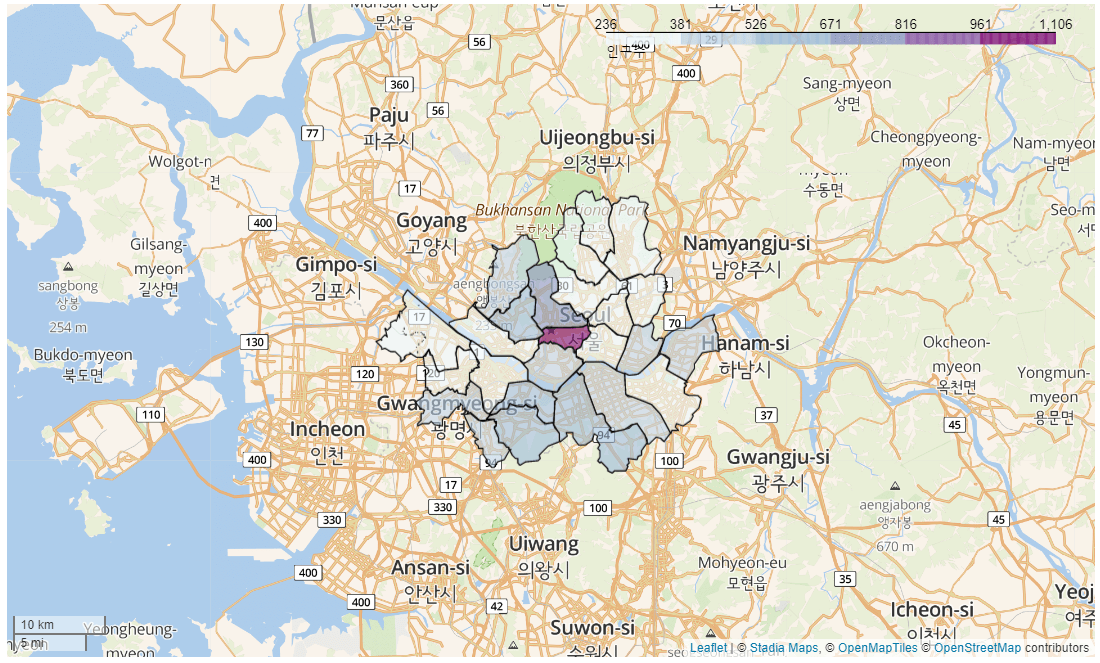
# GeoJson으로 행정구역 경계 표시
import json
with open('data/seoul_muncipalities_geo.json', encoding='utf-8') as file:
geo = json.loads(file.read())
file.close()
구별인구통계.reset_index()
| 구명 | 유동인구수 | |
|---|---|---|
| 0 | 강남구 | 478.024821 |
| 1 | 강동구 | 523.748810 |
| 2 | 강북구 | 369.967532 |
| 3 | 강서구 | 304.261224 |
| 4 | 관악구 | 555.743206 |
| 5 | 광진구 | 405.991209 |
| 6 | 구로구 | 482.763830 |
| 7 | 금천구 | 409.511180 |
| 8 | 노원구 | 327.557143 |
| 9 | 도봉구 | 235.841429 |
| 10 | 동대문구 | 256.464438 |
| 11 | 동작구 | 596.800000 |
| 12 | 마포구 | 355.050794 |
| 13 | 서대문구 | 557.156633 |
| 14 | 서초구 | 557.379617 |
| 15 | 성동구 | 371.584524 |
| 16 | 성북구 | 307.876744 |
| 17 | 송파구 | 286.147768 |
| 18 | 양천구 | 361.187062 |
| 19 | 영등포구 | 380.809821 |
| 20 | 용산구 | 410.963143 |
| 21 | 은평구 | 392.635102 |
| 22 | 종로구 | 799.980451 |
| 23 | 중구 | 1105.794490 |
| 24 | 중랑구 | 250.935714 |
choro = folium.Choropleth(geo_data = geo,
name = 'choropleth',
data = 구별인구통계.reset_index(),
columns = ['구명','유동인구수'],
key_on = 'feature.properties.SIG_KOR_NM',
legend_name = '인구수',
fill_color = 'BuPu').add_to(map1)
map1
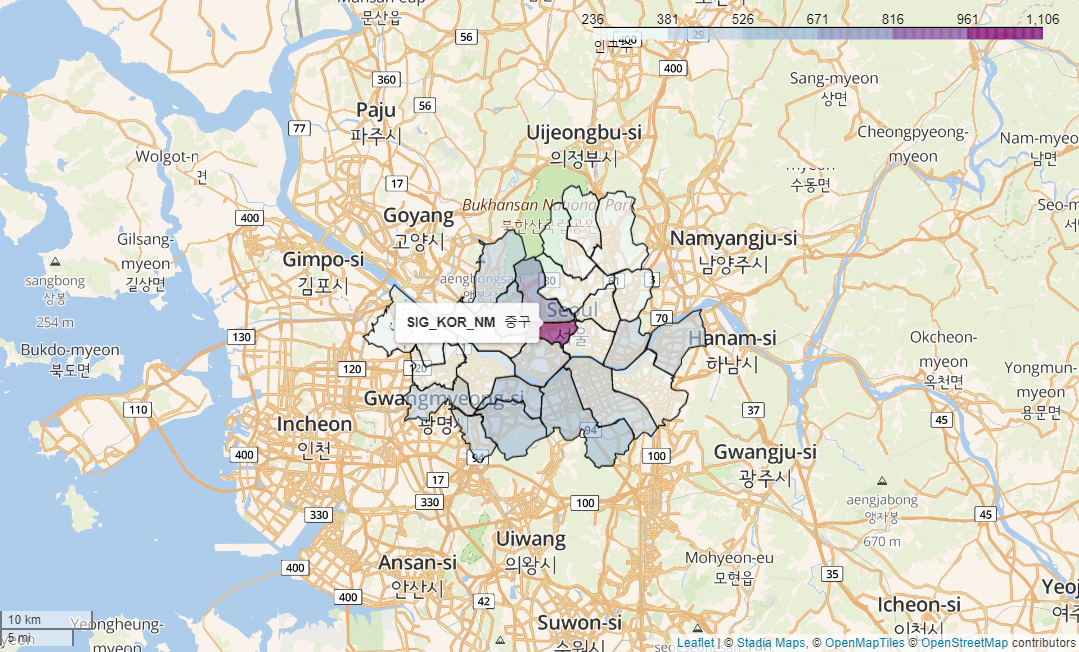
# 호버링 시 구이름 나타나게 하기
choro.geojson.add_child(folium.features.GeoJsonTooltip(['SIG_KOR_NM']))
<folium.features.GeoJson at 0x2b3c4918988>
map1
(실습 #3) 서울시 각 구별로 출퇴근/그 외 시간의 유동인구 분석 (출퇴근 시간은 7시-10시, 18시-21시로 가정함)
최종데이터.head()
| ID유동인구조사 | 조사지점코드 | 조사구분 | 조사요일 | 시간대 | 유동인구수 | 년도 | 조사지점명 | 구코드 | 동코드 | X좌표 | Y좌표 | 구명 | 동명 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 3067 | 01-003 | 본조사 | 금 | 07시-08시 | 21.0 | 2015 | 신흥모피명품전문크리닝. | 11010.0 | 1101055.0 | 196423.97707 | 455511.52968 | 종로구 | 부암동 |
| 1 | 3068 | 01-003 | 본조사 | 금 | 08시-09시 | 36.0 | 2015 | 신흥모피명품전문크리닝. | 11010.0 | 1101055.0 | 196423.97707 | 455511.52968 | 종로구 | 부암동 |
| 2 | 3069 | 01-003 | 본조사 | 금 | 09시-10시 | 27.0 | 2015 | 신흥모피명품전문크리닝. | 11010.0 | 1101055.0 | 196423.97707 | 455511.52968 | 종로구 | 부암동 |
| 3 | 3070 | 01-003 | 본조사 | 금 | 10시-11시 | 51.0 | 2015 | 신흥모피명품전문크리닝. | 11010.0 | 1101055.0 | 196423.97707 | 455511.52968 | 종로구 | 부암동 |
| 4 | 3071 | 01-003 | 본조사 | 금 | 11시-12시 | 36.0 | 2015 | 신흥모피명품전문크리닝. | 11010.0 | 1101055.0 | 196423.97707 | 455511.52968 | 종로구 | 부암동 |
최종데이터['출퇴근여부'] = 최종데이터.시간대.map({
'07시-08시' : '출근',
'08시-09시' : '출근',
'09시-10시' : '출근',
'10시-11시' : '일반',
'11시-12시' : '일반',
'12시-13시' : '일반',
'13시-14시' : '일반',
'14시-15시' : '일반',
'15시-16시' : '일반',
'16시-17시' : '일반',
'17시-18시' : '일반',
'18시-19시' : '퇴근',
'19시-20시' : '퇴근',
'20시-21시' : '퇴근'
})
최종데이터.head(10)
| ID유동인구조사 | 조사지점코드 | 조사구분 | 조사요일 | 시간대 | 유동인구수 | 년도 | 조사지점명 | 구코드 | 동코드 | X좌표 | Y좌표 | 구명 | 동명 | 출퇴근여부 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 3067 | 01-003 | 본조사 | 금 | 07시-08시 | 21.0 | 2015 | 신흥모피명품전문크리닝. | 11010.0 | 1101055.0 | 196423.97707 | 455511.52968 | 종로구 | 부암동 | 출근 |
| 1 | 3068 | 01-003 | 본조사 | 금 | 08시-09시 | 36.0 | 2015 | 신흥모피명품전문크리닝. | 11010.0 | 1101055.0 | 196423.97707 | 455511.52968 | 종로구 | 부암동 | 출근 |
| 2 | 3069 | 01-003 | 본조사 | 금 | 09시-10시 | 27.0 | 2015 | 신흥모피명품전문크리닝. | 11010.0 | 1101055.0 | 196423.97707 | 455511.52968 | 종로구 | 부암동 | 출근 |
| 3 | 3070 | 01-003 | 본조사 | 금 | 10시-11시 | 51.0 | 2015 | 신흥모피명품전문크리닝. | 11010.0 | 1101055.0 | 196423.97707 | 455511.52968 | 종로구 | 부암동 | 일반 |
| 4 | 3071 | 01-003 | 본조사 | 금 | 11시-12시 | 36.0 | 2015 | 신흥모피명품전문크리닝. | 11010.0 | 1101055.0 | 196423.97707 | 455511.52968 | 종로구 | 부암동 | 일반 |
| 5 | 3072 | 01-003 | 본조사 | 금 | 12시-13시 | 48.0 | 2015 | 신흥모피명품전문크리닝. | 11010.0 | 1101055.0 | 196423.97707 | 455511.52968 | 종로구 | 부암동 | 일반 |
| 6 | 3073 | 01-003 | 본조사 | 금 | 13시-14시 | 30.0 | 2015 | 신흥모피명품전문크리닝. | 11010.0 | 1101055.0 | 196423.97707 | 455511.52968 | 종로구 | 부암동 | 일반 |
| 7 | 3074 | 01-003 | 본조사 | 금 | 14시-15시 | 21.0 | 2015 | 신흥모피명품전문크리닝. | 11010.0 | 1101055.0 | 196423.97707 | 455511.52968 | 종로구 | 부암동 | 일반 |
| 8 | 3075 | 01-003 | 본조사 | 금 | 15시-16시 | 30.0 | 2015 | 신흥모피명품전문크리닝. | 11010.0 | 1101055.0 | 196423.97707 | 455511.52968 | 종로구 | 부암동 | 일반 |
| 9 | 3076 | 01-003 | 본조사 | 금 | 16시-17시 | 39.0 | 2015 | 신흥모피명품전문크리닝. | 11010.0 | 1101055.0 | 196423.97707 | 455511.52968 | 종로구 | 부암동 | 일반 |
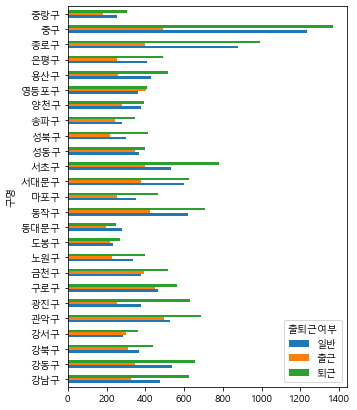
출퇴근시간대유동인구 = 최종데이터.pivot_table(index='구명', columns='출퇴근여부',
values='유동인구수', aggfunc='mean')
출퇴근시간대유동인구.plot(kind='barh', figsize=(5, 7))
<AxesSubplot:ylabel='구명'>
(실습 #4) 평일/주말 유동인구 분석 및 시각화
최종데이터.조사요일.value_counts()
금 16968
수 16968
월 16968
토 16968
화 16968
Name: 조사요일, dtype: int64
# 월, 화, 수 -> 평일(0)
# 금, 토 -> 주말(1)
def 주말여부(x):
if x in ['월','화','수']:
return 0
elif x in ['금','토']:
return 1
else:
return -1
최종데이터['주말여부'] = 최종데이터.조사요일.apply(주말여부)
# 다른방법
최종데이터['주말여부'] = 최종데이터.조사요일.map({
'월':0,
'화':0,
'수':0,
'금':1,
'토':1
})
# 평일/주말별 구별 유동인구
ex4 = 최종데이터.pivot_table(index='구명', columns='주말여부',
values='유동인구수', aggfunc='mean')
ex4.columns = ['평일','주말']
ex4
| 평일 | 주말 | |
|---|---|---|
| 구명 | ||
| 강남구 | 481.161607 | 473.319643 |
| 강동구 | 511.746032 | 541.752976 |
| 강북구 | 366.655844 | 374.935065 |
| 강서구 | 307.132653 | 299.954082 |
| 관악구 | 559.986063 | 549.378920 |
| 광진구 | 398.208791 | 417.664835 |
| 구로구 | 486.550152 | 477.084347 |
| 금천구 | 426.372671 | 384.218944 |
| 노원구 | 326.564386 | 329.046278 |
| 도봉구 | 237.211905 | 233.785714 |
| 동대문구 | 257.907295 | 254.300152 |
| 동작구 | 597.783550 | 595.324675 |
| 마포구 | 345.541005 | 369.315476 |
| 서대문구 | 571.933673 | 534.991071 |
| 서초구 | 551.793554 | 565.758711 |
| 성동구 | 377.960317 | 362.020833 |
| 성북구 | 306.342193 | 310.178571 |
| 송파구 | 279.435268 | 296.216518 |
| 양천구 | 364.090296 | 356.832210 |
| 영등포구 | 379.199777 | 383.224888 |
| 용산구 | 390.315714 | 441.934286 |
| 은평구 | 392.036735 | 393.532653 |
| 종로구 | 775.431391 | 836.804041 |
| 중구 | 1058.997959 | 1175.989286 |
| 중랑구 | 247.295918 | 256.395408 |
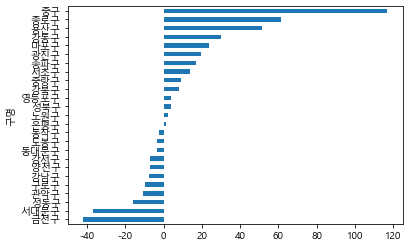
ex4['주말평일차이'] = ex4.주말 - ex4.평일
matplotlib.rcParams['axes.unicode_minus'] = False
# 마이너스 표시 깨짐 방지
ex4.주말평일차이.sort_values().plot(kind='barh')
<AxesSubplot:ylabel='구명'>
(실습 #5) 유동인구의 수와 보행환경 정보를 분석
- 보행환경 정보는 유동인구상세로그_2015.xlsx의 보행환경 컬럼 참고. 매우불만족(1), 약간불만족(2), 보통(3), 약간만족(4), 매우만족(5)
5.1 보행 환경 개선이 시급한 곳 10군데를 선정.
속성조사 = pd.read_excel('data/서울시유동인구/2_유동인구_속성조사_2015.xlsx',
skiprows = [0, 1, 3])
속성조사.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 20000 entries, 0 to 19999
Data columns (total 16 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 ID속성조사 20000 non-null int64
1 조사지점코드 20000 non-null object
2 조사일자 20000 non-null int64
3 조사요일 20000 non-null object
4 남여구분 20000 non-null object
5 조사시간대 0 non-null float64
6 조사시간대_텍스트 20000 non-null object
7 연령대 20000 non-null object
8 거주지 19118 non-null object
9 통행주목적 20000 non-null object
10 방문횟수 20000 non-null object
11 동행자명 0 non-null float64
12 교통수단 0 non-null float64
13 보행환경 20000 non-null object
14 직업명 18574 non-null object
15 년도 20000 non-null int64
dtypes: float64(3), int64(3), object(10)
memory usage: 2.4+ MB
속성조사
| ID속성조사 | 조사지점코드 | 조사일자 | 조사요일 | 남여구분 | 조사시간대 | 조사시간대_텍스트 | 연령대 | 거주지 | 통행주목적 | 방문횟수 | 동행자명 | 교통수단 | 보행환경 | 직업명 | 년도 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 01-003 | 1016 | 금 | 여자 | NaN | 오전11시~오후2시 | 50-54세 | 종로구 | 업무관련 | 주1~2회 | NaN | NaN | 약간만족 | 전문/자유직 | 2015 |
| 1 | 2 | 01-003 | 1016 | 금 | 남자 | NaN | 오전11시~오후2시 | 60-64세 | 성북구 | 업무관련 | 주3~5회 | NaN | NaN | 매우만족 | 일용/작업직 | 2015 |
| 2 | 3 | 01-003 | 1016 | 금 | 남자 | NaN | 오전11시~오후2시 | 65세이상 | 종로구 | 업무관련 | 주3~5회 | NaN | NaN | 약간만족 | 일용/작업직 | 2015 |
| 3 | 4 | 01-003 | 1016 | 금 | 남자 | NaN | 오전7시30분~11시 | 45-49세 | 서대문구 | 출근 | 매일 | NaN | NaN | 약간만족 | 사무/기술직 | 2015 |
| 4 | 5 | 01-003 | 1016 | 금 | 남자 | NaN | 오전7시30분~11시 | 35-39세 | 도봉구 | 출근 | 매일 | NaN | NaN | 매우만족 | 사무/기술직 | 2015 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 19995 | 19996 | 25-463 | 1031 | 토 | 여자 | NaN | 오후5시~8시 | 20-24세 | NaN | 여가/오락/친교/모임/식사(회식,음료포함) | 오늘처음 | NaN | NaN | 보통 | (대)학생 | 2015 |
| 19996 | 19997 | 25-463 | 1031 | 토 | 여자 | NaN | 오후5시~8시 | 45-49세 | 강동구 | 여가/오락/친교/모임/식사(회식,음료포함) | 6개월1~3회 | NaN | NaN | 보통 | (전업)주부 | 2015 |
| 19997 | 19998 | 25-463 | 1031 | 토 | 여자 | NaN | 오전7시30분~11시 | 45-49세 | 강동구 | 회사또는근무지(사업장등)로복귀 | 6개월1~3회 | NaN | NaN | 보통 | 판매/서비스직 | 2015 |
| 19998 | 19999 | 25-463 | 1031 | 토 | 여자 | NaN | 오전7시30분~11시 | 40-44세 | 강동구 | 출근 | 주1~2회 | NaN | NaN | 약간불만족 | 일용/작업직 | 2015 |
| 19999 | 20000 | 25-463 | 1031 | 토 | 남자 | NaN | 오후5시~8시 | 45-49세 | 강동구 | 개인용무/집안일(병원,은행,관공서,종교활동,봉사활동등) | 월1~2회 | NaN | NaN | 매우불만족 | 사무/기술직 | 2015 |
20000 rows × 16 columns
최종데이터.조사지점코드.nunique()
1212
# 조사지점 개수 확인
속성조사.조사지점코드.nunique()
1000
# 전체 조사 다 한건 아님. 전체 1212개 중 딱 1000개만 조사함.
속성조사.조사지점코드.value_counts().value_counts()
# 모든 조사지점에서 20번의 속성조사가 이루어짐
20 1000
Name: 조사지점코드, dtype: int64
속성조사.조사요일.value_counts()
금 10000
토 10000
Name: 조사요일, dtype: int64
속성조사.pivot_table(index = '조사지점코드', columns = '조사요일',
values = 'ID속성조사', aggfunc='count')
속성조사
| ID속성조사 | 조사지점코드 | 조사일자 | 조사요일 | 남여구분 | 조사시간대 | 조사시간대_텍스트 | 연령대 | 거주지 | 통행주목적 | 방문횟수 | 동행자명 | 교통수단 | 보행환경 | 직업명 | 년도 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 01-003 | 1016 | 금 | 여자 | NaN | 오전11시~오후2시 | 50-54세 | 종로구 | 업무관련 | 주1~2회 | NaN | NaN | 약간만족 | 전문/자유직 | 2015 |
| 1 | 2 | 01-003 | 1016 | 금 | 남자 | NaN | 오전11시~오후2시 | 60-64세 | 성북구 | 업무관련 | 주3~5회 | NaN | NaN | 매우만족 | 일용/작업직 | 2015 |
| 2 | 3 | 01-003 | 1016 | 금 | 남자 | NaN | 오전11시~오후2시 | 65세이상 | 종로구 | 업무관련 | 주3~5회 | NaN | NaN | 약간만족 | 일용/작업직 | 2015 |
| 3 | 4 | 01-003 | 1016 | 금 | 남자 | NaN | 오전7시30분~11시 | 45-49세 | 서대문구 | 출근 | 매일 | NaN | NaN | 약간만족 | 사무/기술직 | 2015 |
| 4 | 5 | 01-003 | 1016 | 금 | 남자 | NaN | 오전7시30분~11시 | 35-39세 | 도봉구 | 출근 | 매일 | NaN | NaN | 매우만족 | 사무/기술직 | 2015 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 19995 | 19996 | 25-463 | 1031 | 토 | 여자 | NaN | 오후5시~8시 | 20-24세 | NaN | 여가/오락/친교/모임/식사(회식,음료포함) | 오늘처음 | NaN | NaN | 보통 | (대)학생 | 2015 |
| 19996 | 19997 | 25-463 | 1031 | 토 | 여자 | NaN | 오후5시~8시 | 45-49세 | 강동구 | 여가/오락/친교/모임/식사(회식,음료포함) | 6개월1~3회 | NaN | NaN | 보통 | (전업)주부 | 2015 |
| 19997 | 19998 | 25-463 | 1031 | 토 | 여자 | NaN | 오전7시30분~11시 | 45-49세 | 강동구 | 회사또는근무지(사업장등)로복귀 | 6개월1~3회 | NaN | NaN | 보통 | 판매/서비스직 | 2015 |
| 19998 | 19999 | 25-463 | 1031 | 토 | 여자 | NaN | 오전7시30분~11시 | 40-44세 | 강동구 | 출근 | 주1~2회 | NaN | NaN | 약간불만족 | 일용/작업직 | 2015 |
| 19999 | 20000 | 25-463 | 1031 | 토 | 남자 | NaN | 오후5시~8시 | 45-49세 | 강동구 | 개인용무/집안일(병원,은행,관공서,종교활동,봉사활동등) | 월1~2회 | NaN | NaN | 매우불만족 | 사무/기술직 | 2015 |
20000 rows × 16 columns
속성조사.보행환경.value_counts().sort_index()
매우만족 772
매우불만족 2388
보통 9533
약간만족 2563
약간불만족 4744
Name: 보행환경, dtype: int64
속성조사['보행점수'] = 속성조사.보행환경.map({
'매우불만족':1,
'약간불만족':2,
'보통':3,
'약간만족':4,
'매우만족':5
})
속성조사
| ID속성조사 | 조사지점코드 | 조사일자 | 조사요일 | 남여구분 | 조사시간대 | 조사시간대_텍스트 | 연령대 | 거주지 | 통행주목적 | 방문횟수 | 동행자명 | 교통수단 | 보행환경 | 직업명 | 년도 | 보행점수 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 01-003 | 1016 | 금 | 여자 | NaN | 오전11시~오후2시 | 50-54세 | 종로구 | 업무관련 | 주1~2회 | NaN | NaN | 약간만족 | 전문/자유직 | 2015 | 4 |
| 1 | 2 | 01-003 | 1016 | 금 | 남자 | NaN | 오전11시~오후2시 | 60-64세 | 성북구 | 업무관련 | 주3~5회 | NaN | NaN | 매우만족 | 일용/작업직 | 2015 | 5 |
| 2 | 3 | 01-003 | 1016 | 금 | 남자 | NaN | 오전11시~오후2시 | 65세이상 | 종로구 | 업무관련 | 주3~5회 | NaN | NaN | 약간만족 | 일용/작업직 | 2015 | 4 |
| 3 | 4 | 01-003 | 1016 | 금 | 남자 | NaN | 오전7시30분~11시 | 45-49세 | 서대문구 | 출근 | 매일 | NaN | NaN | 약간만족 | 사무/기술직 | 2015 | 4 |
| 4 | 5 | 01-003 | 1016 | 금 | 남자 | NaN | 오전7시30분~11시 | 35-39세 | 도봉구 | 출근 | 매일 | NaN | NaN | 매우만족 | 사무/기술직 | 2015 | 5 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 19995 | 19996 | 25-463 | 1031 | 토 | 여자 | NaN | 오후5시~8시 | 20-24세 | NaN | 여가/오락/친교/모임/식사(회식,음료포함) | 오늘처음 | NaN | NaN | 보통 | (대)학생 | 2015 | 3 |
| 19996 | 19997 | 25-463 | 1031 | 토 | 여자 | NaN | 오후5시~8시 | 45-49세 | 강동구 | 여가/오락/친교/모임/식사(회식,음료포함) | 6개월1~3회 | NaN | NaN | 보통 | (전업)주부 | 2015 | 3 |
| 19997 | 19998 | 25-463 | 1031 | 토 | 여자 | NaN | 오전7시30분~11시 | 45-49세 | 강동구 | 회사또는근무지(사업장등)로복귀 | 6개월1~3회 | NaN | NaN | 보통 | 판매/서비스직 | 2015 | 3 |
| 19998 | 19999 | 25-463 | 1031 | 토 | 여자 | NaN | 오전7시30분~11시 | 40-44세 | 강동구 | 출근 | 주1~2회 | NaN | NaN | 약간불만족 | 일용/작업직 | 2015 | 2 |
| 19999 | 20000 | 25-463 | 1031 | 토 | 남자 | NaN | 오후5시~8시 | 45-49세 | 강동구 | 개인용무/집안일(병원,은행,관공서,종교활동,봉사활동등) | 월1~2회 | NaN | NaN | 매우불만족 | 사무/기술직 | 2015 | 1 |
20000 rows × 17 columns
# 보행환경 개선이 시급한 지역
# 보행점수와 유동인구를 함께 고려
지점별보행점수 = 속성조사.pivot_table(index = '조사지점코드', values = '보행점수',
aggfunc='mean')
지점별보행점수
| 보행점수 | |
|---|---|
| 조사지점코드 | |
| 01-003 | 3.90 |
| 01-005 | 2.35 |
| 01-008 | 2.60 |
| 01-009 | 3.05 |
| 01-016 | 2.60 |
| ... | ... |
| 25-242 | 2.75 |
| 25-408 | 2.75 |
| 25-430 | 1.70 |
| 25-434 | 3.80 |
| 25-463 | 2.60 |
1000 rows × 1 columns
지점별유동인구 = 최종데이터.pivot_table(index = '조사지점코드', values = '유동인구수',
aggfunc='mean')
지점별유동인구
| 유동인구수 | |
|---|---|
| 조사지점코드 | |
| 01-003 | 41.357143 |
| 01-004 | 198.171429 |
| 01-005 | 150.128571 |
| 01-008 | 75.942857 |
| 01-009 | 80.528571 |
| ... | ... |
| 25-408 | 1548.042857 |
| 25-430 | 1371.985714 |
| 25-434 | 114.085714 |
| 25-463 | 218.100000 |
| 25-815 | 602.014286 |
1212 rows × 1 columns
ex5 = pd.concat([지점별보행점수, 지점별유동인구], axis=1, join='inner') # 기본값=없는값도Nan으로포함=outer
ex5 # merge는 기본값이 inner (반대)
| 보행점수 | 유동인구수 | |
|---|---|---|
| 조사지점코드 | ||
| 01-003 | 3.90 | 41.357143 |
| 01-005 | 2.35 | 150.128571 |
| 01-008 | 2.60 | 75.942857 |
| 01-009 | 3.05 | 80.528571 |
| 01-016 | 2.60 | 889.542857 |
| ... | ... | ... |
| 25-242 | 2.75 | 328.200000 |
| 25-408 | 2.75 | 1548.042857 |
| 25-430 | 1.70 | 1371.985714 |
| 25-434 | 3.80 | 114.085714 |
| 25-463 | 2.60 | 218.100000 |
992 rows × 2 columns
ex5.info()
<class 'pandas.core.frame.DataFrame'>
Index: 992 entries, 01-003 to 25-463
Data columns (total 2 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 보행점수 992 non-null float64
1 유동인구수 992 non-null float64
dtypes: float64(2)
memory usage: 23.2+ KB
# 보행점수가 2점 미만인 지역 중 유동인구가 많은 10개 지역 선정
개선시급지역 = ex5[ex5.보행점수 < 2].nlargest(10, '유동인구수')
개선시급지역
| 보행점수 | 유동인구수 | |
|---|---|---|
| 조사지점코드 | ||
| 01-213 | 1.95 | 3368.914286 |
| 17-2055 | 1.45 | 3242.828571 |
| 01-2095 | 1.20 | 2193.857143 |
| 23-076 | 1.90 | 1928.142857 |
| 01-084 | 1.85 | 1831.928571 |
| 02-260 | 1.70 | 1810.328571 |
| 17-082 | 1.70 | 1572.342857 |
| 01-082 | 1.90 | 1502.528571 |
| 23-034 | 1.35 | 1389.728571 |
| 25-430 | 1.70 | 1371.985714 |
# 개선시급지역을 지도에 시각화
개선시급지역= 개선시급지역.reset_index()
개선시급지역 = pd.merge(개선시급지역, 조사지점[['조사지점코드','조사지점명','X좌표','Y좌표']])
개선시급지역
| 조사지점코드 | 보행점수 | 유동인구수 | 조사지점명 | X좌표 | Y좌표 | |
|---|---|---|---|---|---|---|
| 0 | 01-213 | 1.95 | 3368.914286 | cafe nanuri | 198528.06633 | 453727.84806 |
| 1 | 17-2055 | 1.45 | 3242.828571 | 디큐브시티 | 190016.40000 | 445484.99021 |
| 2 | 01-2095 | 1.20 | 2193.857143 | 동아일보 | 198026.60682 | 452265.43991 |
| 3 | 23-076 | 1.90 | 1928.142857 | 코끼리상가 | 202812.00572 | 447645.09507 |
| 4 | 01-084 | 1.85 | 1831.928571 | 광화문 빌딩 | 197893.71130 | 452255.02517 |
| 5 | 02-260 | 1.70 | 1810.328571 | 스타벅스 | 198571.61688 | 451327.19366 |
| 6 | 17-082 | 1.70 | 1572.342857 | 자전거 주차장 | 190463.23371 | 445313.73349 |
| 7 | 01-082 | 1.90 | 1502.528571 | 준코 뮤직타운 | 198721.18954 | 452307.83355 |
| 8 | 23-034 | 1.35 | 1389.728571 | capital tower 앞 | 203045.16639 | 444620.39654 |
| 9 | 25-430 | 1.70 | 1371.985714 | 신동아생활용품DC마트 | 211375.75228 | 450168.33297 |
from pyproj import Proj, transform
def convert_loc(x,y):
inProj = Proj(init='epsg:5181')
outProj = Proj(init='epsg:4326')
x2, y2 = transform(inProj, outProj, x, y)
return [y2, x2]
import warnings
warnings.filterwarnings("ignore")
개선시급지역['위경도']=개선시급지역.apply(lambda 최종데이터: convert_loc(최종데이터.X좌표, 최종데이터.Y좌표), axis=1)
개선시급지역
| 조사지점코드 | 보행점수 | 유동인구수 | 조사지점명 | X좌표 | Y좌표 | 위경도 | |
|---|---|---|---|---|---|---|---|
| 0 | 01-213 | 1.95 | 3368.914286 | cafe nanuri | 198528.06633 | 453727.84806 | [37.58310456094619, 126.98333547159028] |
| 1 | 17-2055 | 1.45 | 3242.828571 | 디큐브시티 | 190016.40000 | 445484.99021 | [37.50878369212982, 126.8870826364644] |
| 2 | 01-2095 | 1.20 | 2193.857143 | 동아일보 | 198026.60682 | 452265.43991 | [37.56992740808484, 126.97766212376528] |
| 3 | 23-076 | 1.90 | 1928.142857 | 코끼리상가 | 202812.00572 | 447645.09507 | [37.528295993738254, 127.03181287428026] |
| 4 | 01-084 | 1.85 | 1831.928571 | 광화문 빌딩 | 197893.71130 | 452255.02517 | [37.569833277541, 126.9761578394427] |
| 5 | 02-260 | 1.70 | 1810.328571 | 스타벅스 | 198571.61688 | 451327.19366 | [37.56147485263183, 126.98383320628312] |
| 6 | 17-082 | 1.70 | 1572.342857 | 자전거 주차장 | 190463.23371 | 445313.73349 | [37.50724538640684, 126.89213866497093] |
| 7 | 01-082 | 1.90 | 1502.528571 | 준코 뮤직타운 | 198721.18954 | 452307.83355 | [37.57031059866805, 126.98552439699829] |
| 8 | 23-034 | 1.35 | 1389.728571 | capital tower 앞 | 203045.16639 | 444620.39654 | [37.501042607485395, 127.03443814970538] |
| 9 | 25-430 | 1.70 | 1371.985714 | 신동아생활용품DC마트 | 211375.75228 | 450168.33297 | [37.55096447551782, 127.12873547021874] |
for x, y in 개선시급지역.위경도:
print(type(x))
<class 'float'>
<class 'float'>
<class 'float'>
<class 'float'>
<class 'float'>
<class 'float'>
<class 'float'>
<class 'float'>
<class 'float'>
<class 'float'>
for idx, val in 개선시급지역.iterrows():
print(val.위경도)
[37.58310456094619, 126.98333547159028]
[37.50878369212982, 126.8870826364644]
[37.56992740808484, 126.97766212376528]
[37.528295993738254, 127.03181287428026]
[37.569833277541, 126.9761578394427]
[37.56147485263183, 126.98383320628312]
[37.50724538640684, 126.89213866497093]
[37.57031059866805, 126.98552439699829]
[37.501042607485395, 127.03443814970538]
[37.55096447551782, 127.12873547021874]
map4 = folium.Map(location=[37.566535, 126.9779691999996], zoom_start=10,
zoom_control=False, control_scale=True,
tiles='https://tiles.stadiamaps.com/tiles/outdoors/{z}/{x}/{y}{r}.png',
attr='© <a href="https://stadiamaps.com/">Stadia Maps</a>, © <a href="https://openmaptiles.org/">OpenMapTiles</a> © <a href="http://openstreetmap.org">OpenStreetMap</a> contributors')
map4
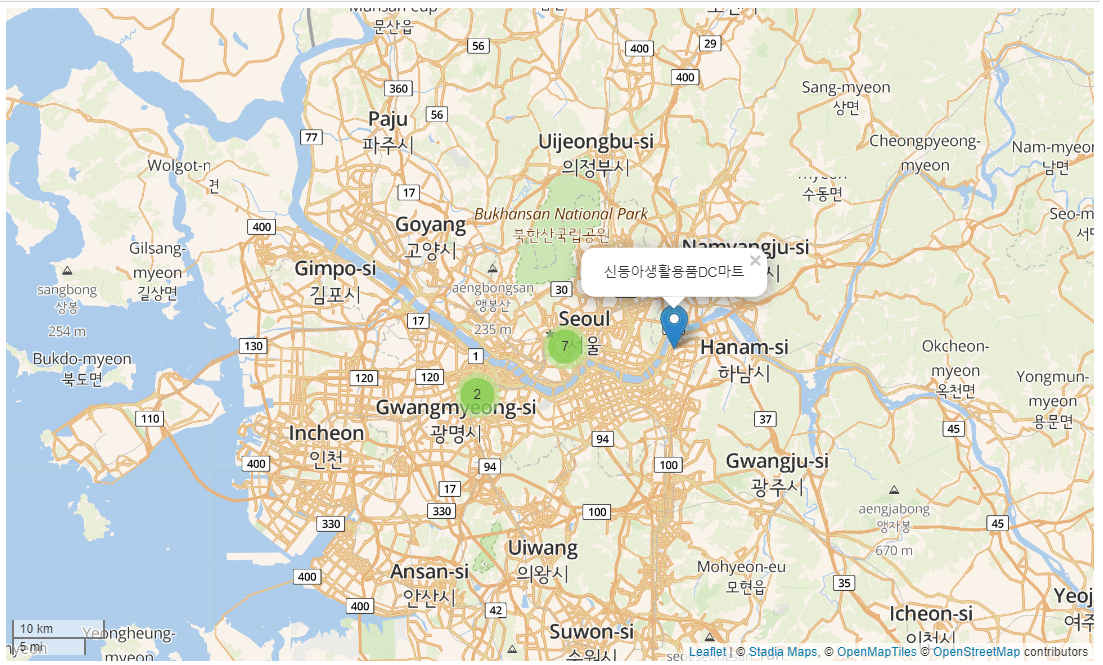
from folium.plugins import MarkerCluster
marker_cluster = MarkerCluster().add_to(map4)
for idx, val in 개선시급지역.iterrows():
#print(val)
folium.Marker(location=val.위경도, popup=folium.Popup(val.조사지점명, max_width=300))\
.add_to(marker_cluster)
map4
from folium.plugins import MarkerCluster
marker_cluster = MarkerCluster().add_to(map4)
for idx, val in 개선시급지역.iterrows():
#print(val)
msg = '조사지점명:{0}<br> 유동인구수:{1}<br> 보행점수:{2}'.format(val.조사지점명, val.유동인구수, val.보행점수)
folium.Marker(location=val.위경도, popup=folium.Popup(msg, max_width=300))\
.add_to(marker_cluster)
map4
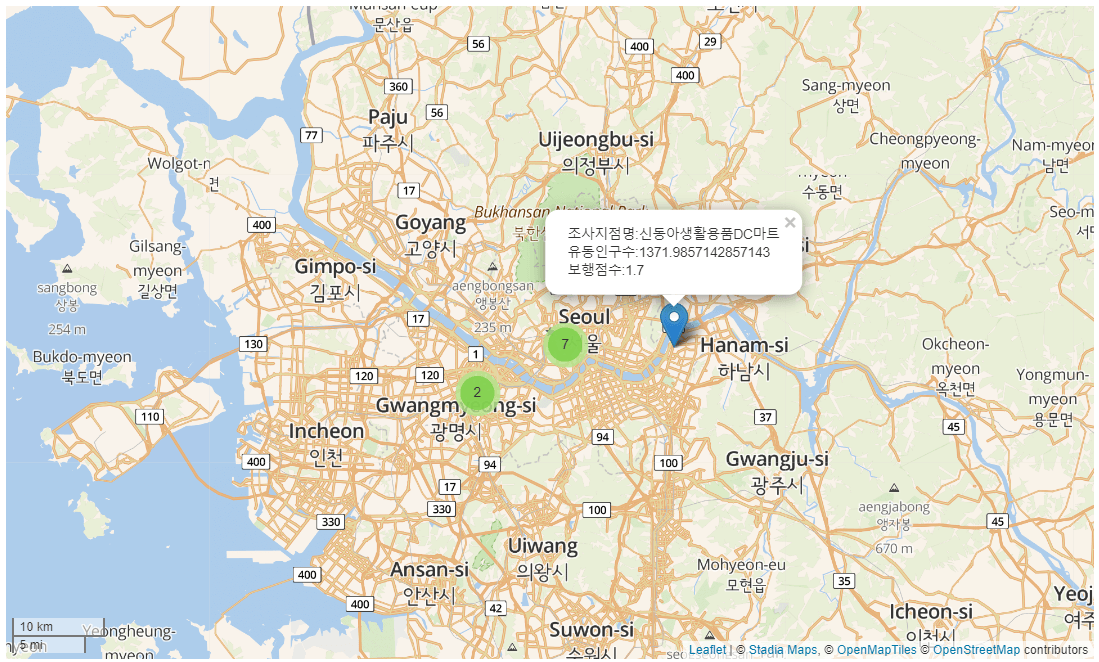
5.2 구별 보행환경점수 지도 시각화
ex5 = ex5.reset_index()
ex5
| 조사지점코드 | 보행점수 | 유동인구수 | |
|---|---|---|---|
| 0 | 01-003 | 3.90 | 41.357143 |
| 1 | 01-005 | 2.35 | 150.128571 |
| 2 | 01-008 | 2.60 | 75.942857 |
| 3 | 01-009 | 3.05 | 80.528571 |
| 4 | 01-016 | 2.60 | 889.542857 |
| ... | ... | ... | ... |
| 987 | 25-242 | 2.75 | 328.200000 |
| 988 | 25-408 | 2.75 | 1548.042857 |
| 989 | 25-430 | 1.70 | 1371.985714 |
| 990 | 25-434 | 3.80 | 114.085714 |
| 991 | 25-463 | 2.60 | 218.100000 |
992 rows × 3 columns
ex5 = pd.merge(ex5, 조사지점[['조사지점코드','구코드']], on='조사지점코드')
ex5 = pd.merge(ex5, 구코드[['구코드','구명']])
ex5
| 조사지점코드 | 보행점수 | 유동인구수 | 구코드 | 구명 | |
|---|---|---|---|---|---|
| 0 | 01-003 | 3.90 | 41.357143 | 11010.0 | 종로구 |
| 1 | 01-005 | 2.35 | 150.128571 | 11010.0 | 종로구 |
| 2 | 01-008 | 2.60 | 75.942857 | 11010.0 | 종로구 |
| 3 | 01-009 | 3.05 | 80.528571 | 11010.0 | 종로구 |
| 4 | 01-016 | 2.60 | 889.542857 | 11010.0 | 종로구 |
| ... | ... | ... | ... | ... | ... |
| 987 | 25-242 | 2.75 | 328.200000 | 11250.0 | 강동구 |
| 988 | 25-408 | 2.75 | 1548.042857 | 11250.0 | 강동구 |
| 989 | 25-430 | 1.70 | 1371.985714 | 11250.0 | 강동구 |
| 990 | 25-434 | 3.80 | 114.085714 | 11250.0 | 강동구 |
| 991 | 25-463 | 2.60 | 218.100000 | 11250.0 | 강동구 |
992 rows × 5 columns
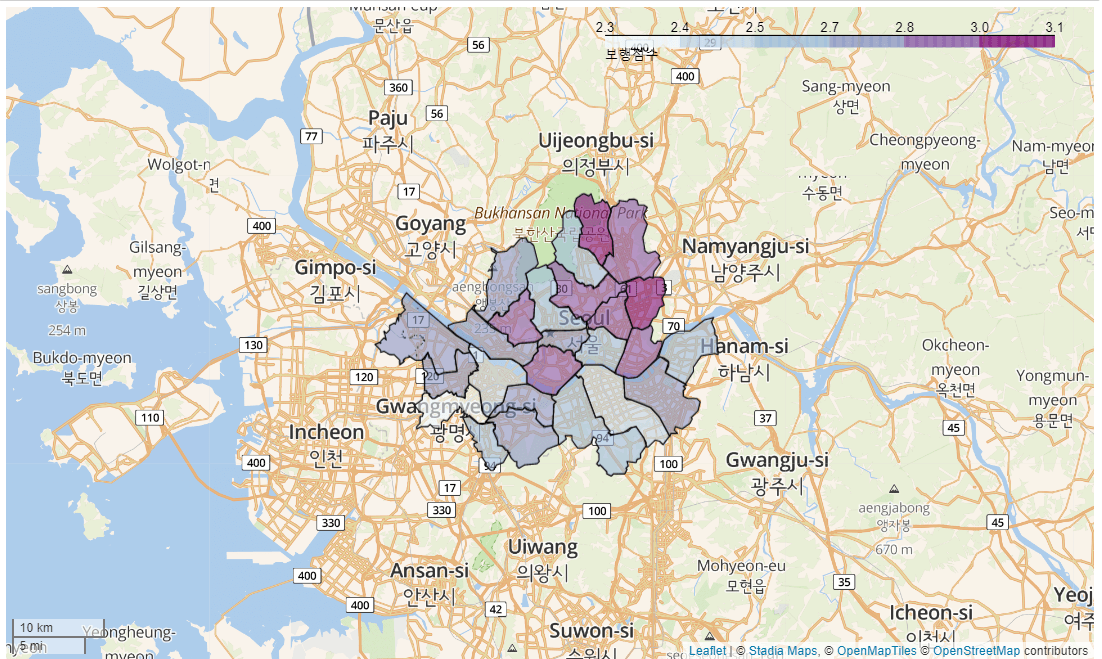
구별보행점수 = ex5.pivot_table(index='구명', values='보행점수', aggfunc='mean')
구별보행점수
| 보행점수 | |
|---|---|
| 구명 | |
| 강남구 | 2.455072 |
| 강동구 | 2.646774 |
| 강북구 | 2.646296 |
| 강서구 | 2.765517 |
| 관악구 | 2.843548 |
| 광진구 | 2.961765 |
| 구로구 | 2.250000 |
| 금천구 | 2.697368 |
| 노원구 | 2.920161 |
| 도봉구 | 3.002000 |
| 동대문구 | 2.853571 |
| 동작구 | 2.700000 |
| 마포구 | 2.750000 |
| 서대문구 | 2.900000 |
| 서초구 | 2.605797 |
| 성동구 | 2.571667 |
| 성북구 | 2.866667 |
| 송파구 | 2.733333 |
| 양천구 | 2.814286 |
| 영등포구 | 2.490566 |
| 용산구 | 2.867500 |
| 은평구 | 2.817241 |
| 종로구 | 2.600000 |
| 중구 | 2.802000 |
| 중랑구 | 3.145946 |
import json
with open('data/seoul_muncipalities_geo.json', encoding='utf-8') as file:
geo=json.loads(file.read())
file.close()
map2 = folium.Map(location=[37.566535, 126.9779691999996], zoom_start=10,
zoom_control=False, control_scale=True,
tiles='https://tiles.stadiamaps.com/tiles/outdoors/{z}/{x}/{y}{r}.png',
attr='© <a href="https://stadiamaps.com/">Stadia Maps</a>, © <a href="https://openmaptiles.org/">OpenMapTiles</a> © <a href="http://openstreetmap.org">OpenStreetMap</a> contributors')
map2
구별보행점수 = 구별보행점수.reset_index()
folium.Choropleth(geo_data = geo,
name = 'choropleth',
data = 구별보행점수,
columns = ['구명','보행점수'],
key_on = 'feature.properties.SIG_KOR_NM',
legend_name = '보행점수',
fill_color = 'BuPu',
highlight = True
).add_to(map2)
<folium.features.Choropleth at 0x2b3c6e29408>
choro.geojson.add_child(
folium.features.GeoJsonTooltip(['SIG_KOR_NM'], labels=False))
<folium.features.GeoJson at 0x2b3c4918988>
map2